FraudBuster
Cloud-native distributed system for detecting fake, irrelevant, and AI-generated e-commerce reviews through real-time scraping, machine learning, and scalable microservices.
Project Overview
FraudBuster is a cloud-native distributed system built to detect fake, generic, and AI-generated reviews at scale. The platform combines live review scraping, machine learning inference, and a microservices architecture to generate trustworthiness summaries for e-commerce products. It was designed as a real-time system rather than an offline prototype, allowing users to submit a product URL and receive an instant credibility evaluation.
Key Highlights
Designed a cloud-native microservices architecture with separate services for scraping, classification, scoring, caching, and scheduling.
Built an AI-powered review classifier using a fine-tuned BERT model to distinguish machine-generated and authentic reviews.
Implemented a semantic relevance scoring service to detect off-topic and generic reviews using sentence-transformer embeddings.
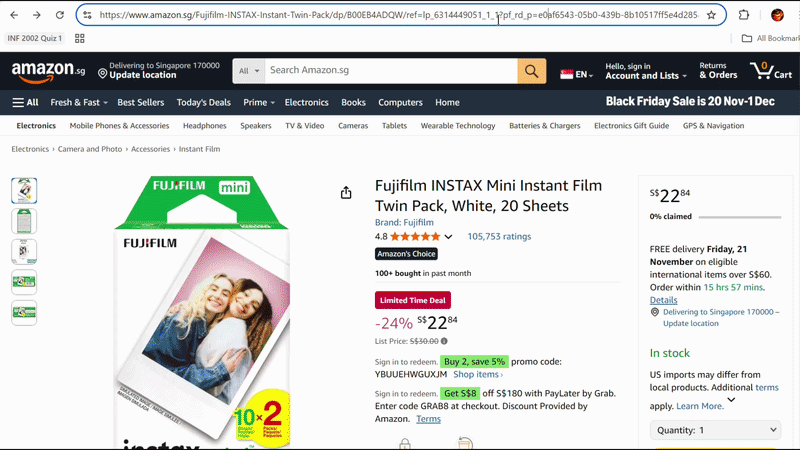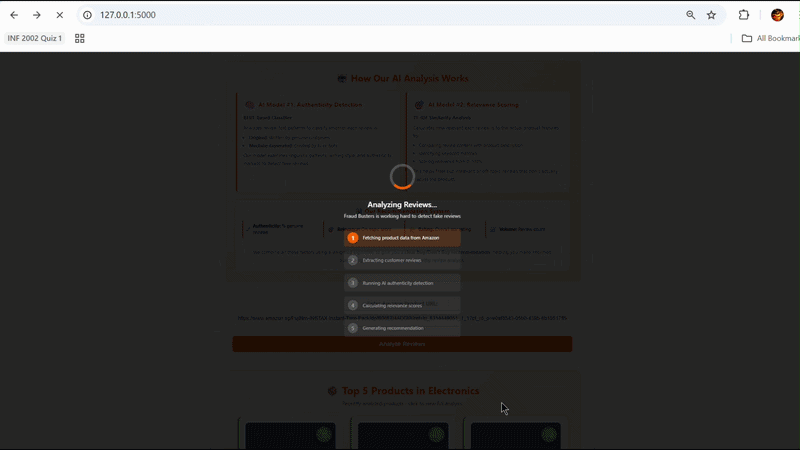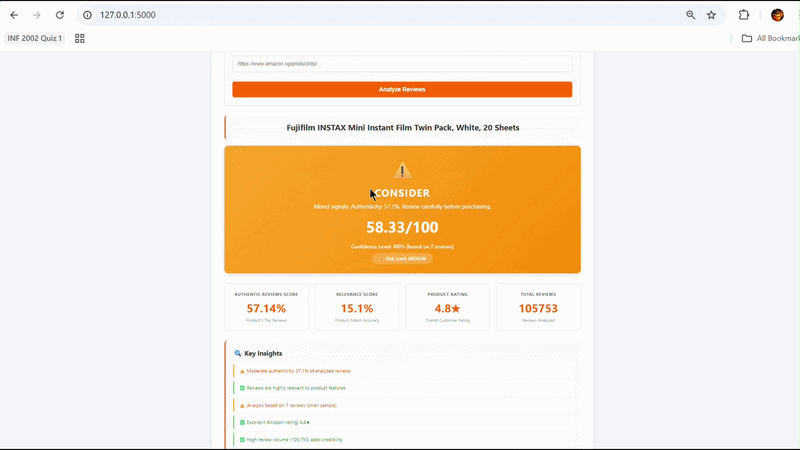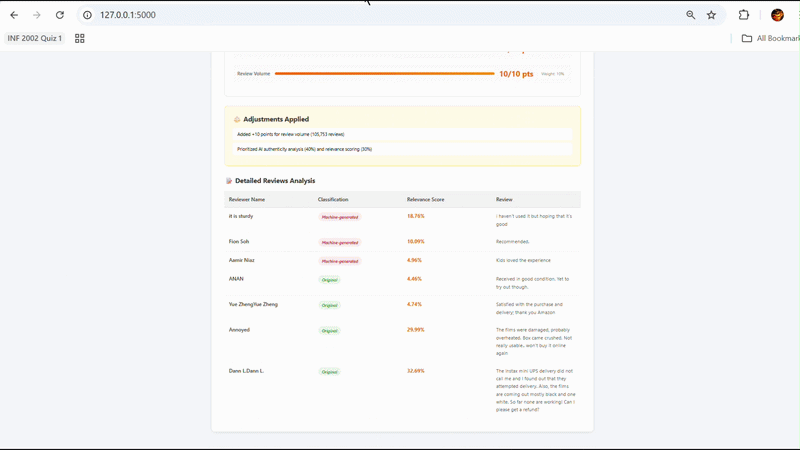
Developed a hybrid recommendation engine that combines authenticity, relevance, ratings, and review volume into BUY / CONSIDER / CAUTION / AVOID outputs.
Optimized performance with Redis caching, MongoDB persistence, and Kubernetes autoscaling for scalable review analysis.
Used gRPC for low-latency inter-service communication and deployed health checks, CronJobs, and monitoring for production-style reliability.
Problem
E-commerce platforms are increasingly affected by fake, generic, and AI-generated reviews. These distort ratings, mislead users, and make it harder for consumers to judge product quality accurately. Existing approaches are often closed, manual, or not designed for real-time, scalable analysis of live product URLs.
Solution
FraudBuster introduces a real-time analysis pipeline where users submit a product URL and the system dynamically scrapes reviews, classifies authenticity, scores semantic relevance, and synthesizes the results into a recommendation. Internally, the system uses a cache → database → scraper decision chain to reduce unnecessary scraping, while Kubernetes-managed microservices enable independent scaling of compute-heavy components such as the BERT classifier and relevance scorer.
Outcome
The project delivered a production-style system that combines distributed systems, applied AI, and cloud-native deployment. It strengthened my experience in microservices design, ML inference pipelines, Kubernetes autoscaling, caching strategies, and low-latency inter-service communication. It also demonstrated how architecture decisions directly affect performance, reliability, and user experience in high-volume environments.