EcoPrompt
Cloud-native middleware that optimizes LLM prompts to reduce token usage, cost, and energy consumption without modifying existing applications.
Project Overview
EcoPrompt acts as a middleware layer that processes and optimizes prompts before they are sent to large language models. By removing redundancy, compressing input, and avoiding repeated requests, it improves efficiency without requiring changes to upstream systems.
Key Highlights
Designed a cloud-native microservices architecture for prompt optimization and analytics
Built a multi-stage pipeline combining rule-based cleaning and T5 (LoRA) compression
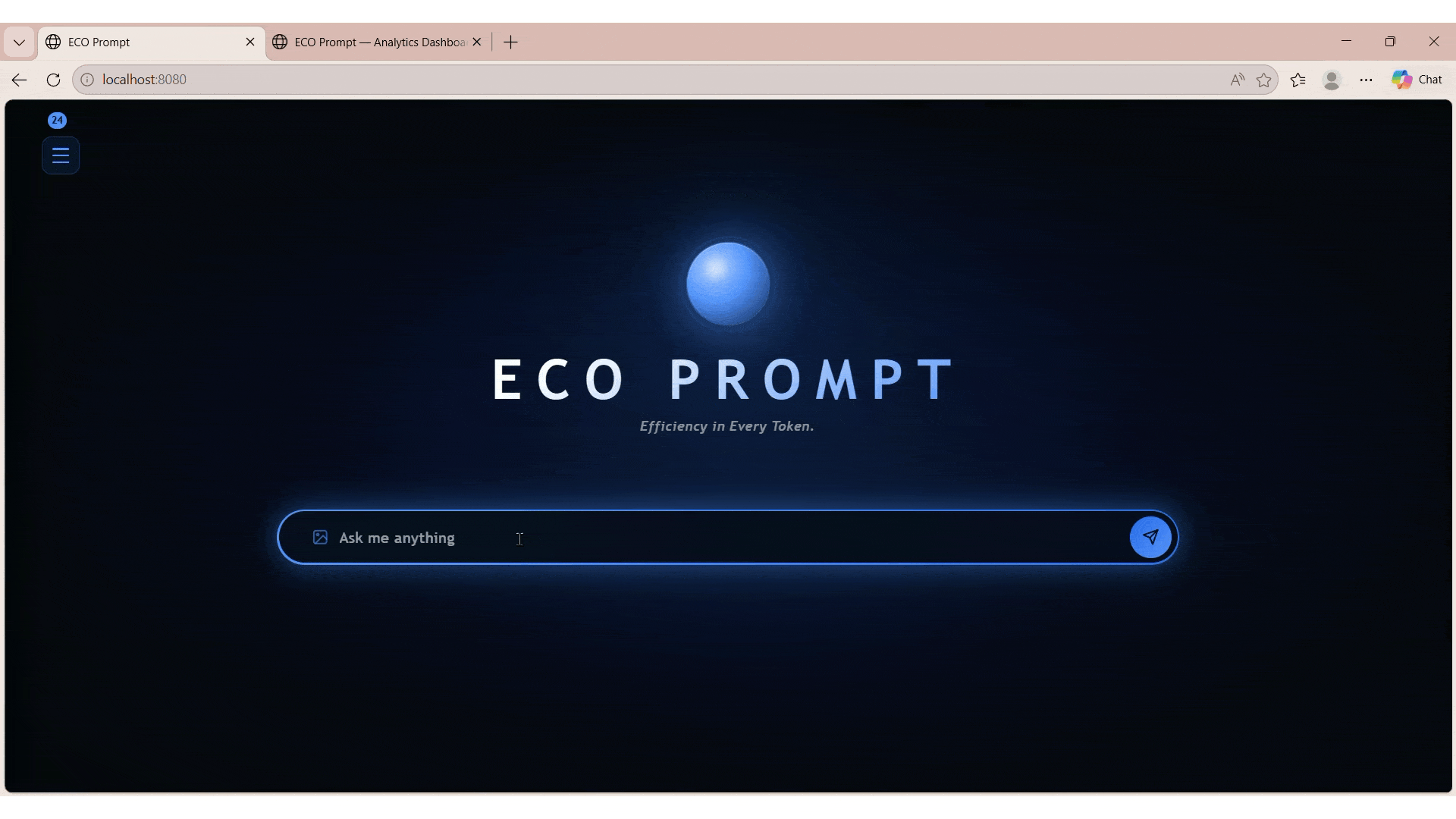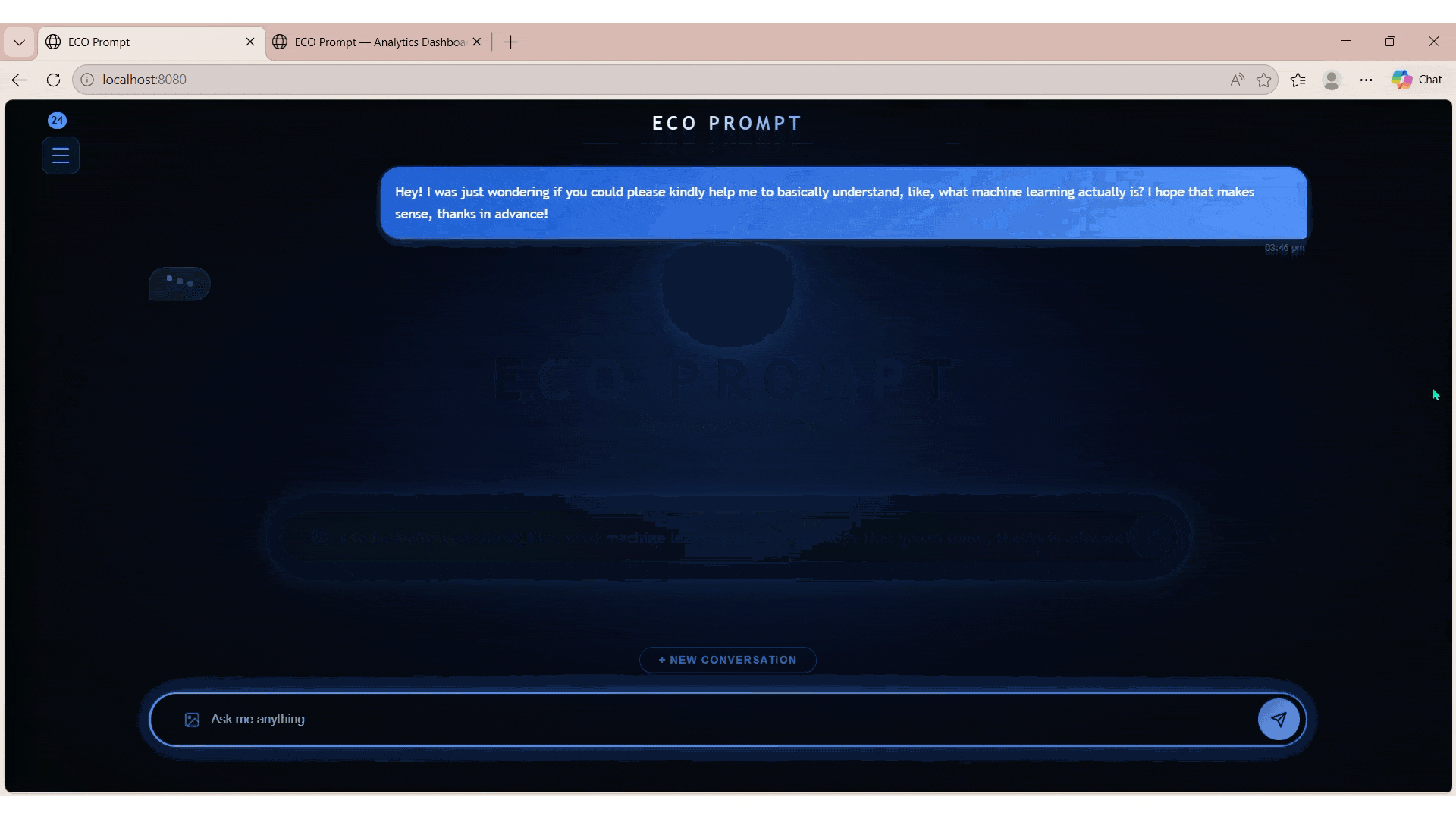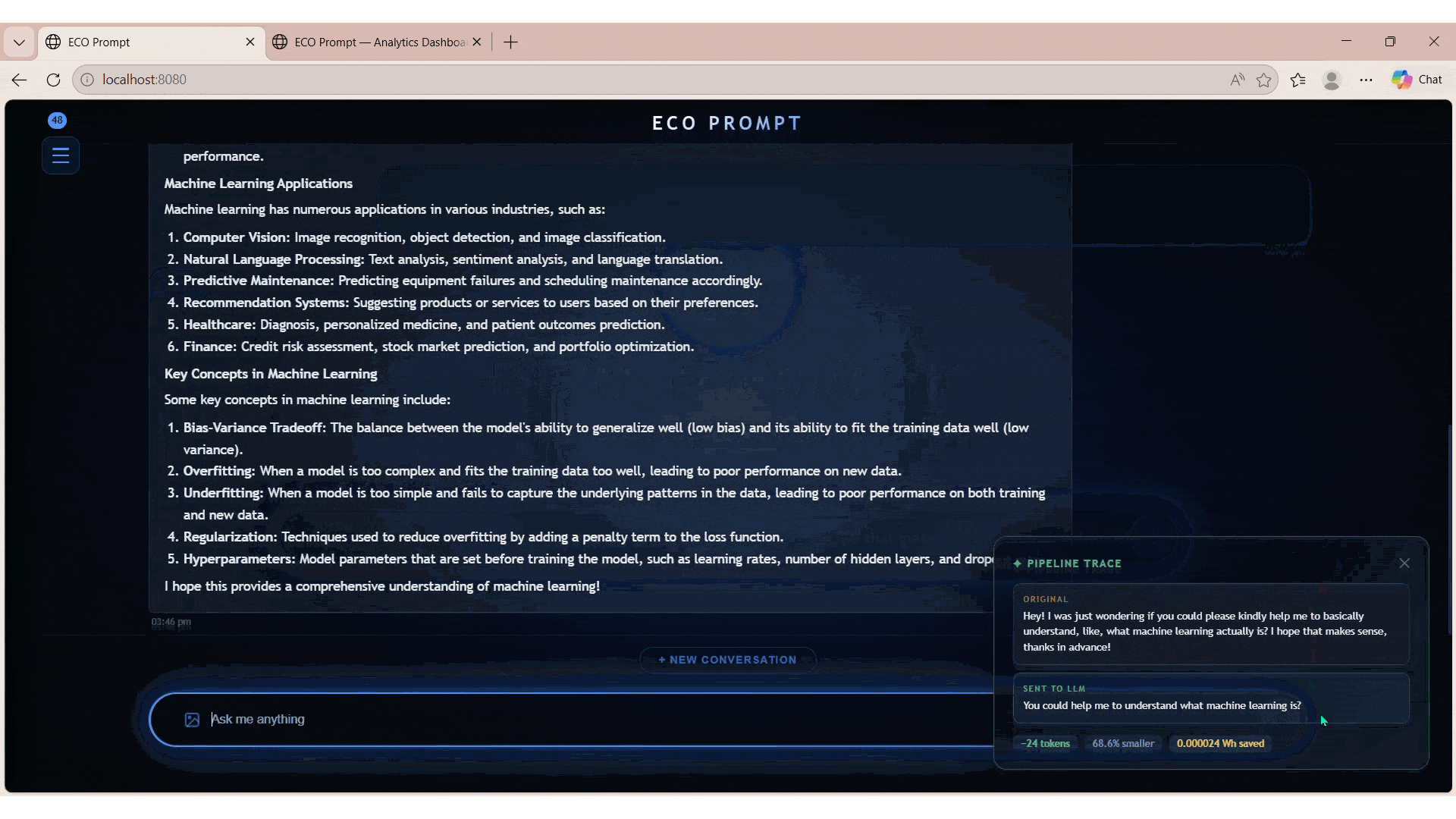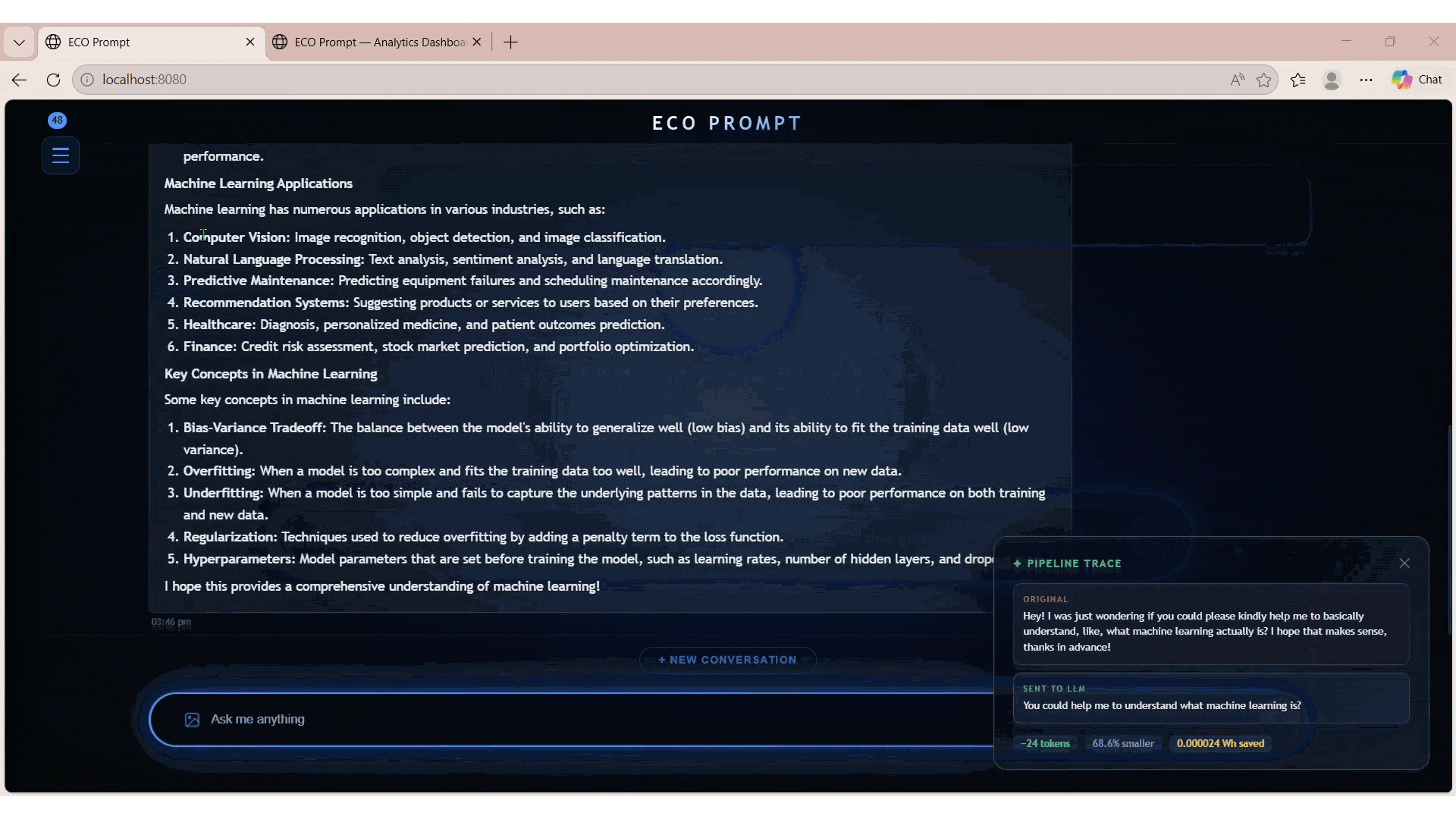
Implemented semantic caching using TF-IDF similarity to eliminate redundant LLM calls
Deployed services using Docker and Kubernetes with autoscaling capabilities
Tracked token savings, cost reduction, and estimated CO₂ impact through analytics service
Problem
LLM-based applications often send verbose and repetitive prompts, leading to unnecessary token consumption, higher API costs, and increased energy usage. At scale, this inefficiency significantly impacts system performance and cost.
Solution
EcoPrompt introduces a multi-stage pipeline combining rule-based cleaning, AI-based compression using T5 (LoRA), and semantic caching via TF-IDF. This ensures prompts remain concise, relevant, and are not redundantly processed.
Outcome
The system achieved measurable token reduction and cost savings while maintaining output quality. It demonstrates strong capabilities in distributed systems, cloud-native deployment, and applied AI optimization.